We now introduce, Auxilliary Networks, additions to the basic Injective Network architecture that enhances their representation power.
# Basic imports
import torch
from torch import nn
import geosimilarity as gs
from NIGnets import NIGnet
from assets.utils import automate_training, plot_curvesPre-Auxilliary Networks¶
Closed Condition: A Closer Look¶
Let’s first try fitting an Injective Network to a square using the PReLU function. Indeed as
discussed before the PReLU activation does not guarantee non-self-intersection but
we use it to gain insights.
from assets.shapes import square
# Generate target curve points
num_pts = 1000
t = torch.linspace(0, 1, num_pts).reshape(-1, 1)
Xt_square = square(num_pts)
square_net = NIGnet(layer_count = 3, act_fn = nn.PReLU)
automate_training(
model = square_net, loss_fn = gs.MSELoss(), X_train = t, Y_train = Xt_square,
learning_rate = 0.1, epochs = 1000, print_cost_every = 200
)
Xp_square = square_net(t)
plot_curves(Xp_square, Xt_square)Epoch: [ 1/1000]. Loss: 1.052965
Epoch: [ 200/1000]. Loss: 0.006894
Epoch: [ 400/1000]. Loss: 0.006118
Epoch: [ 600/1000]. Loss: 0.005084
Epoch: [ 800/1000]. Loss: 0.003844
Epoch: [1000/1000]. Loss: 0.003531
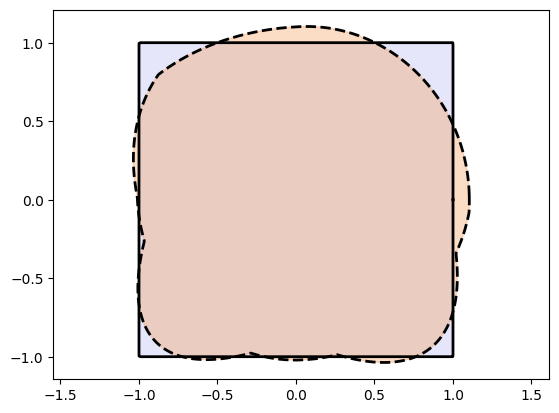
We observe that the fit is really bad.
This is because the network first transforms the interval to a circle and then deeper layers try to transform that to a square. This is not an easy task as the network has to transform the circle arcs to the four straight edges.
Let’s have a look at the first transformation as discussed in the section Condition 2 - Closed Curves:
The point is a point on the unit circle centered at the origin. What is happening here is that the open interval is transformed to a circle that makes sure that the first and the last point are the same and when fed into the network lead to the same output point and hence create closed curves. This is explained visually in Figure 5.
![Transforming the line segment [0, 1] to the unit circle centered at the origin.](/NIGnets/build/closed_condition_lin-6292735ada9a2a6097938c485f8cdfe8.svg)
Figure 5:Transforming the line segment to the unit circle centered at the origin.
We could have also achieved the closed condition by transforming to a square instead of a circle.
For the above problem of fitting to a square this should help immensely as the Injective Network has
to learn the identity mapping only! This is easy to do when using the PReLU activation.
Code for transforming to unit square
def square_from_t(t: torch.Tensor) -> torch.Tensor:
# Generate theta values corresponding to t
theta = 2 * torch.pi * t.reshape(-1)
x, y = torch.cos(theta), torch.sin(theta)
s = torch.maximum(torch.abs(x), torch.abs(y))
x_sq, y_sq = x/s, y/s
X = torch.stack([x_sq, y_sq], dim = 1)
return Xfrom assets.shapes import square_from_t
class InjectiveNet_SquareClosed(nn.Module):
def __init__(self, layer_count, act_fn):
super().__init__()
# Transform from t on the [0, 1] interval to unit square for closed shapes
self.closed_transform = square_from_t
layers = []
for i in range(layer_count):
layers.append(nn.Linear(2, 2))
layers.append(act_fn())
self.linear_act_stack = nn.Sequential(*layers)
def forward(self, t):
x = self.closed_transform(t)
x = self.linear_act_stack(x)
return x# Generate target curve points
num_pts = 1000
t = torch.linspace(0, 1, num_pts).reshape(-1, 1)
X_t_square = square(num_pts)
square_net = InjectiveNet_SquareClosed(layer_count = 1, act_fn = nn.PReLU)
automate_training(
model = square_net, loss_fn = gs.MSELoss(), X_train = t, Y_train = X_t_square,
learning_rate = 0.1, epochs = 1000, print_cost_every = 200
)
X_p_square = square_net(t)
plot_curves(X_p_square, X_t_square)
# Print model parameters after learning
for name, param in square_net.named_parameters():
print(f"Layer: {name} | Values : {param[:2]} \n")Epoch: [ 1/1000]. Loss: 0.579582
Epoch: [ 200/1000]. Loss: 0.000000
Epoch: [ 400/1000]. Loss: 0.000000
Epoch: [ 600/1000]. Loss: 0.000000
Epoch: [ 800/1000]. Loss: 0.000000
Epoch: [1000/1000]. Loss: 0.000000
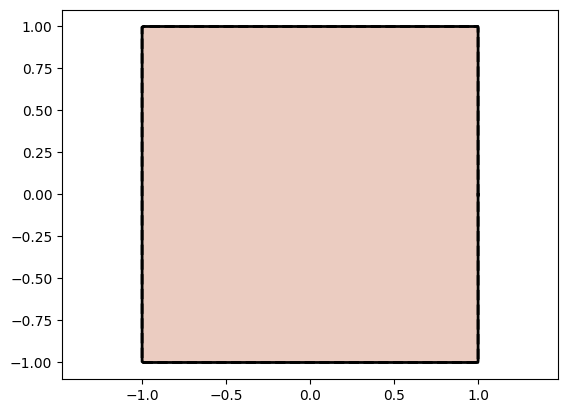
Layer: linear_act_stack.0.weight | Values : tensor([[1.0000e+00, 1.6361e-08],
[2.4072e-09, 1.0000e+00]], grad_fn=<SliceBackward0>)
Layer: linear_act_stack.0.bias | Values : tensor([-1.3566e-07, -6.1809e-08], grad_fn=<SliceBackward0>)
Layer: linear_act_stack.1.weight | Values : tensor([1.0000], grad_fn=<SliceBackward0>)
Observe above that the network indeed learns the identity mapping as the linear transformation matrix ends up as the identity matrix and the PReLU activation function ends up as that is the identity map with the slope as 1 and bias being 0.
Pre-Auxilliary Network¶
Indeed we could have transformed to any simple closed curve first and then attached the neural network layers after that. But since representing general simple closed curves is what we are trying to achieve, we can do a simpler thing. We transform the interval to a closed loop represented through polar coordinates in the form:
where with in .
We can then use the vector as the first layer and attach the usual Injective Network layers on top. This transformation from to the vector is injective and satisfies the condition and thus will create closed curves.
The function can be represented using a full neural network with no additional constraints except that the output has to be positive. We call this network the Pre-Auxilliary Network.
The basic idea is that the Pre-Auxilliary Network will provide a favorable initial shape to the Injective Network and make its learning task simpler.
Using Pre-Auxilliary Networks with NIGnets is really simple! Just create an appropriate network and pass that to the NIGnets constructor. We demonstrate this below.
The power of PreAux nets lies in the fact that a full scale MLP can be used to represent them. But a few conditions must be met to create a valid PreAux Net:
class PreAuxNet(nn.Module):
def __init__(self, layer_count, hidden_dim):
super().__init__()
# Pre-Auxilliary net needs closed transform to get same r at theta = 0, 2pi
self.closed_transform = lambda t: torch.hstack([
torch.cos(2 * torch.pi * t),
torch.sin(2 * torch.pi * t)
])
layers = [nn.Linear(2, hidden_dim), nn.ReLU()]
for i in range(layer_count):
layers.append(nn.Linear(hidden_dim, hidden_dim))
layers.append(nn.ReLU())
layers.append(nn.Linear(hidden_dim, 1))
layers.append(nn.ReLU())
self.forward_stack = nn.Sequential(*layers)
def forward(self, t):
unit_circle = self.closed_transform(t) # Rows are cos(theta), sin(theta)
r = self.forward_stack(unit_circle)
x = r * unit_circle # Each row is now r*cos(theta), r*sin(theta)
return xfrom assets.shapes import square
# Generate target curve points
num_pts = 1000
t = torch.linspace(0, 1, num_pts).reshape(-1, 1)
Xt_square = square(num_pts)
preaux_net = PreAuxNet(layer_count = 3, hidden_dim = 10)
square_net = NIGnet(layer_count = 1, act_fn = nn.PReLU, preaux_net = preaux_net)
automate_training(
model = square_net, loss_fn = gs.MSELoss(), X_train = t, Y_train = Xt_square,
learning_rate = 0.1, epochs = 1000, print_cost_every = 200
)
Xp_square = square_net(t)
plot_curves(Xp_square, Xt_square)Epoch: [ 1/1000]. Loss: 0.976244
Epoch: [ 200/1000]. Loss: 0.000039
Epoch: [ 400/1000]. Loss: 0.000025
Epoch: [ 600/1000]. Loss: 0.000031
Epoch: [ 800/1000]. Loss: 0.000035
Epoch: [1000/1000]. Loss: 0.000036
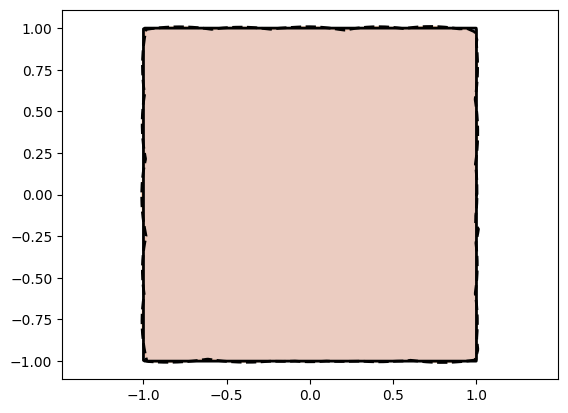
Great! Using a Pre-Auxilliary Network helps us build an Injective Network on top of a favorable closed transform. This therefore helps us cover both the circle and the square fitting cases without specifying a particular initial transform such as the circle or square. Pre-Auxilliary Networks are therefore a way of adding to the capacity of Injective Networks using full scale neural networks.
from assets.shapes import stanford_bunny
# Generate target curve points
num_pts = 1000
t = torch.linspace(0, 1, num_pts).reshape(-1, 1)
Xt_bunny = stanford_bunny(num_pts)
preaux_net = PreAuxNet(layer_count = 2, hidden_dim = 50)
bunny_net = NIGnet(layer_count = 1, act_fn = nn.PReLU, preaux_net = preaux_net)
automate_training(
model = bunny_net, loss_fn = gs.MSELoss(), X_train = t, Y_train = Xt_bunny,
learning_rate = 0.1, epochs = 1000, print_cost_every = 200
)
Xp_bunny = bunny_net(t)
plot_curves(Xp_bunny, Xt_bunny)Epoch: [ 1/1000]. Loss: 0.550154
Epoch: [ 200/1000]. Loss: 0.005555
Epoch: [ 400/1000]. Loss: 0.004586
Epoch: [ 600/1000]. Loss: 0.004364
Epoch: [ 800/1000]. Loss: 0.004427
Epoch: [1000/1000]. Loss: 0.004183
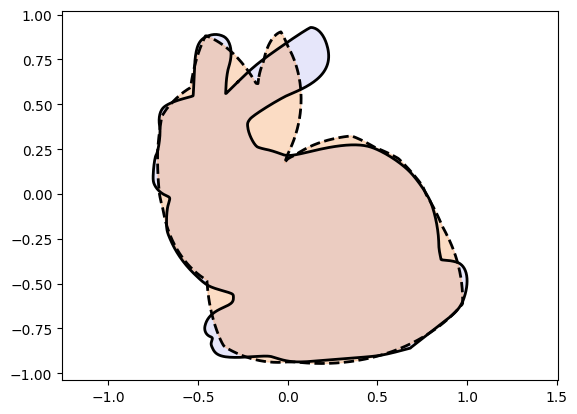
We now look at another technique that allows us to use full scale neural networks to augment the power of Injective Networks.
Post-Auxilliary Networks¶
More Representation Power: Augmenting in Polar Coordinates¶
The Injective Network architecture can represent simple closed curves. But as we saw the requirement of network injectivity for imparting non-self-intersection to the parameterization restricted the hidden layer size to 2. Therefore the only thing we can control for increasing representation power is the network depth.
There is a way of working with polar coordinates where we can post-augment the parameterization with a general neural network giving a boost to representation power. We discuss this technique now. But first we need to discuss the polar version of the Injective Network.
Polar Neural Injective Geometry¶
Consider first a polar setup of the parameterization similar to the cartesian case:
Again as before we look at a vector-valued equivalent:
We use the same network architecture as before with the only difference that now the output is :

Figure 2:The network architecture for polar representation of simple closed curves looks deceptively similar to the one for cartesian coordinates with only the interpretation of the outputs being instead of . But for the polar representation we need more constraints to hold to guarantee simple closed curves.
The network architecture for the polar representation looks deceptively similar to the one for cartesian coordinates with only the interpretation of the outputs being instead of . But for the polar representation we need additional constraints to hold to guarantee simple closed curves.
- Positive
The polar representation requires that is positive. The above architecture by default puts no restriction on what values can take. To generate only positive values the activation function used at the last layer should be such that its outputs are always positive. Note that this activation function should still be injective. Valid activation functions include , , modified or etc. An example modification of would be to add 1 to it and use as the final activation function, this works as is injective with range .
- Restricting
Once we make sure that we choose the right activation function that only outputs positive values we need to make sure of the range of for a couple of reasons:
The first is related to self-intersection. The mapping from is injective. But the curve it may trace out in the current form may self-intersect. Consider as an e.g. the points and . These are different outputs and does not violate injectivity of the network but they correspond to the same point in the plane!
The second one is a representation problem. Let’s say we use the last layer activation function to be . This function has the range and therefore this will also be the possible that we can generate. Thus, our curves will all be limited to . Of course, this is an artifact of using and a different activation function like the would not have this issue, but it will suffer from the first issue above.
Therefore the possible activation functions we can use at the last layer must be restricted to those that can further be scaled to have a range . One valid choice would be the function .
Note: There is then also the concern on the range of r.
Post-Auxilliary Networks¶
Now consider a polar representation of the form:
As we discussed before this is a guaranteed non-self-intersecting representation but suffers from the general curve representation problem discussed in the section Naive Usage of Polar Coordinates: The Representation Power Problem.
But this can be a very powerful representation as we can use a full scale neural network to parameterize . We now see a way of combining the injective polar representation with this parameterization.
Note: The final activation function of the neural network should be chosen such that the outputs are always positive to agree with being positive.
Probably the simplest thing to do would be to simply add the outputs of the two networks. One would do this by adding the value output from the auxilliary network to the different values that are output from the injective network at any given . But performing this directly has a problem. The auxilliary network is defined at all by definition but the injective network may not output some values of and therefore we cannot add the two. This is shown in Figure 3.

Figure 3:We cannot add the two networks at since the injective network does not output all possible as varies from .
But there is a simple way of bypassing this problem. The basic idea is to use values only at values that lead to valid . The valid are generated as . Therefore the corresponding are the values generated at valid that occur as is traversed from .
Consider a vector-valued mapping associated with the auxilliary network:
Note this requires that we first feed in into the injective network, get the corresponding and then feed that into the auxilliary network to generate the for the mapping.
We now have the following two vector-valued mappings:
Consider the addition of these:
We now need to prove that this mapping generates simple closed curves. This is quite intuitive and the proof is as follows:
- Closed
- The curves will be closed if . But we have as is the injective network. That is, We have and . Now since we also have and hence the curves will be closed.
- Simple
- The curves will be simple if the mapping is injective. Which is true if: We start with the assumption that is not injective. That is for some and the outputs are the same. Then we have: and But this means that which is a contradiction as is the injective network. Therefore our original assumption that is not injective is false, and we conclude that the mapping is indeed injective.
Figure 4 shows the architecture for the augmented network

Figure 4:First is fed into the injective network to obtain its and output. This is then fed into the auxilliary network to generate which is then added to to generate the final value.