# Basic imports
import torch
from torch import nn
import geosimilarity as gs
from assets.utils import automate_training, plot_curvesCreating Injective Functions with Parameters¶
We observed earlier that with the PReLU activation Injective Networks
perform much better. Therefore, the insight we gain that will help us power up Injective Networks is
: add more parameters.
One way to add parameters to the Network is to use parameterized activation functions e.g. i.e. the sigmoid with a parameter or try and create other activations. During the creation of these parameterized activations one needs to keep in mind that injectivity should not be violated for any parameter value to ensure that the network always represents only simple closed curves, which is our final goal.
It is quite difficult to combine activation functions together with appropriate parameters that add representation power while maintaining injectivity. We will therefore look at a much more drastic and interesting approach.
First, we need to understand how we could create a function that is injective. The first step is to realize that:
A continuous function is injective if and only if it is strictly monotonic.[1]
Therefore we can create injective functions by creating strictly monotonic functions.
Monotonic Networks: A Superpower¶
We will create injective activation functions using a drastic measure. Every activation function will be an injective neural network!
We will create neural networks that take in a scalar input and output a scalar value and are strictly monotonic in the input. Mathematically our activation function now is a neural network
which satisfies one of:
Monotonic Networks
We will choose neural networks that by design for any parameter value are always monotonic, these are called Monotonic Networks.
Every activation layer will be an independent Monotonic Network and all neurons will use the same neural network. This is shown in Figure 1.

Figure 1:Injective Network with Monotonic Networks as activation functions. shown in the figure is a monotonic network.
Building Monotonic Networks with Smooth Min-Max Networks¶
Building Monotonic Networks is an active area of research and there are a few popular choices. The first Monotonic Network was designed by Sill (1997) which used and operations to impart monotonicity. But since the operations are not differentiable they are hard to train and also suffer from dead neurons[2]. Recently Igel (2023) proposed a variation of the original Monotonic Networks proposed by Sill (1997), which replaces the hard with their smooth variants. These are called Smooth Min-Max Monotonic Networks.
We will use Smooth Min-Max Monotonic Networks as activation functions to augment Injective Networks.
We use the code provided in Christian’s Repository
https://
Note: To ensure positive weights for monotonicity constraints we provide two options.
Exponential positivity: - Igel (2023) and Sill (1997)
Squared positivity: - Daniels & Velikova (2010)
By default monotonic networks provided in the NIGnets module use squared positivity constraints as they were found to perform slightly better.
To use monotonic networks with NIGnets, create a monotonic network of a particular architecture and pass that as an input to NIGnets. NIGnets under the hood creates deepcopies using the same architecture and uses different monotonic networks at each layer. The NIGnets package comes with an implementation of some popular monotonic networks that can be used directly without installing additional dependencies.
from NIGnets import NIGnet
from NIGnets.monotonic_nets import SmoothMinMaxNet
monotonic_net = SmoothMinMaxNet(input_dim = 1, n_groups = 6, nodes_per_group = 6)
bunny_net = NIGnet(layer_count = 5, monotonic_net = monotonic_net)
# Ignore the line below for now, we explain that later when we talk about skip connections
bunny_net.skip_connections = Falsefrom assets.shapes import stanford_bunny
# Generate target curve points
num_pts = 1000
t = torch.linspace(0, 1, num_pts).reshape(-1, 1)
Xt_bunny = stanford_bunny(num_pts)
automate_training(
model = bunny_net, loss_fn = gs.MSELoss(), X_train = t, Y_train = Xt_bunny,
learning_rate = 0.1, epochs = 10000, print_cost_every = 2000
)
Xc_bunny = bunny_net(t)
plot_curves(Xc_bunny, Xt_bunny)Epoch: [ 1/10000]. Loss: 0.817833
Epoch: [ 2000/10000]. Loss: 0.001536
Epoch: [ 4000/10000]. Loss: 0.000603
Epoch: [ 6000/10000]. Loss: 0.000363
Epoch: [ 8000/10000]. Loss: 0.000280
Epoch: [10000/10000]. Loss: 0.000265
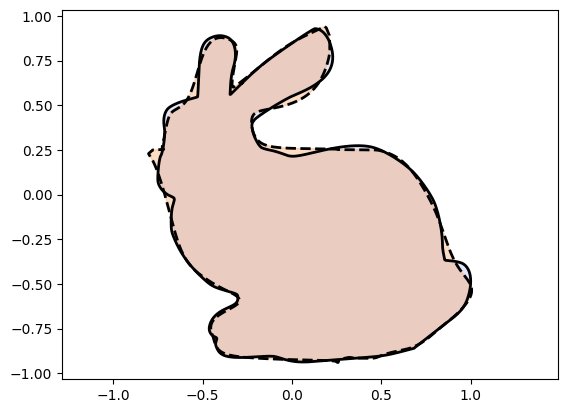
We observe an amazing improvement! Using Monotonic Networks as activation functions bolsters Injective Networks by introducing a lot of parameters which can be tuned to fit shapes with high accuracy.
Skip Connections: ResNet Style¶
The Residual Network (ResNet) architecture has made training easier for deeper networks. We can similarly use skip connections with monotonic networks as they preserve monotonicity and hence injectivity. This will allow us to train deeper NIGnets. The skip connection connects the input with the output of a subnetwork. This is shown in Figure 2.

Figure 2:Skip connections connect the input with the output of a subnetwork . This allows gradients to flow directly from the loss to each layer.
We now see that we can have skip connections after each layer in NIGnets and still maintain injectivity of the layers separately and therefore of the network as a whole.
- Linear Layers
- Each linear layer performs the operation . Adding a skip connection would lead to: A skip connection is mathematically unnecessary in a mathematical sense as we can think of any transformation to be composed of and view as our weight matrix for the layer instead. In fact using skip connections with the Impossible Self-Intersection can lead to non-invertible matrices and violate the hard guarantee on injectivity. This is because even though is always invertible, is not and may even be the 0 matrix. Thus, we do not use skip connections with the linear layer.
- Nonlinear Layers
- For the nonlinear transformations we use some injective scalar-valued mapping, which is either an activation function or a monotonic network. Assuming that the mapping is an increasing monotonic function . Then we have the layer’s transformation to be: Taking derivative, now since is an increasing monotonic function, is positive and hence we also have, Thus the resulting transformation is also an increasing monotonic function. The derivative being always greater than 1, might be a concern and we could additionally also include a positively constrained scaling to as: with,
NIGnets uses a squared positivity constraint and uses the scaling with being the parameter.
from NIGnets import NIGnet
from NIGnets.monotonic_nets import SmoothMinMaxNet
monotonic_net = SmoothMinMaxNet(input_dim = 1, n_groups = 6, nodes_per_group = 6)
bunny_net = NIGnet(layer_count = 5, monotonic_net = monotonic_net)from assets.shapes import stanford_bunny
# Generate target curve points
num_pts = 1000
t = torch.linspace(0, 1, num_pts).reshape(-1, 1)
Xt_bunny = stanford_bunny(num_pts)
automate_training(
model = bunny_net, loss_fn = gs.MSELoss(), X_train = t, Y_train = Xt_bunny,
learning_rate = 0.1, epochs = 10000, print_cost_every = 2000
)
Xc_bunny = bunny_net(t)
plot_curves(Xc_bunny, Xt_bunny)Epoch: [ 1/10000]. Loss: 0.471980
Epoch: [ 2000/10000]. Loss: 0.009097
Epoch: [ 4000/10000]. Loss: 0.000485
Epoch: [ 6000/10000]. Loss: 0.000278
Epoch: [ 8000/10000]. Loss: 0.000202
Epoch: [10000/10000]. Loss: 0.000188
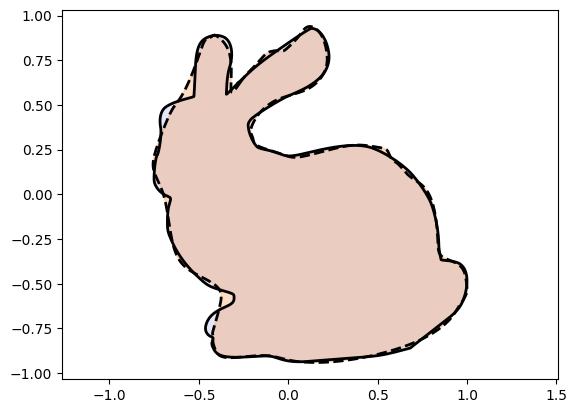
Training dynamics and performance with skip connections we find to be so good that NIGnets by
default uses skip connections. To not use skip connections pass in the additional argument
skip_connections = False to the NIGnet constructor.
Math StackExchange, Continuous injective map is strictly monotonic
Data Science StackExchange What is the “dying ReLU” problem in neural networks?
- Sill, J. (1997). Monotonic networks. Advances in Neural Information Processing Systems, 10.
- Igel, C. (2023). Smooth Min-Max Monotonic Networks. arXiv Preprint arXiv:2306.01147.
- Runje, D., & Shankaranarayana, S. M. (2023). Constrained monotonic neural networks. International Conference on Machine Learning, 29338–29353.
- Daniels, H., & Velikova, M. (2010). Monotone and partially monotone neural networks. IEEE Transactions on Neural Networks, 21(6), 906–917.